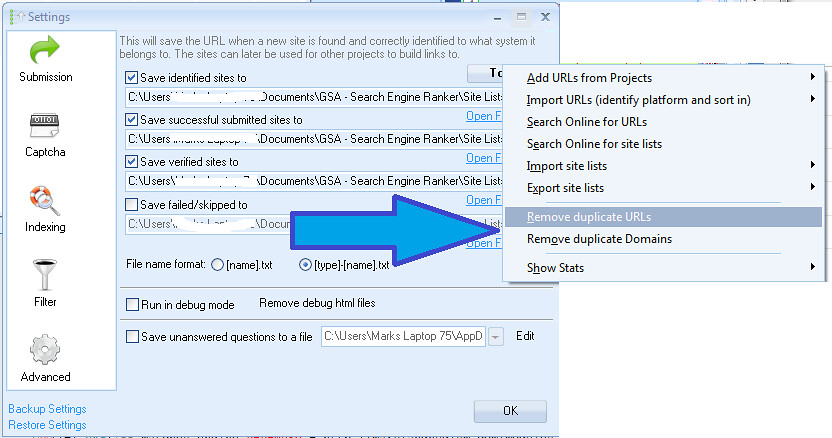
They impact all the lists you have. They remove duplicate domains or duplicate URL's.
I use both these options every week.
LeeG Eating your first bourne
I only every use remove duplicate urls. And do a couple of hundred thousand to a million every couple of days when I run it
Duplicate domains, I do not touch
But thats just my own preference and how I build my own links
honor90
edited January 2013
Thanks everyone for the help!
@Ozz, sorry, I should know at this point to look at that thread
P.s @LeeG, that's the way that I like to do things too.
rodol
@globalgoogler why you will remove duplicates domain that is not smart
pietpatat
edited January 2013
I also remove dupe domains, don't see why you wouldn't do this as this will keep your sitelist nice and clean for some max efficiency.
Lets say I run a new project and have use sitelist turned on. It will grab 100 urls from the sitelist, but if 50 of these are from the same domain it will say 49 times: "already parsed" right? Because it tried to post to the first url and after that it will identify: hey I have already tried to post on this domain so I will output: already parsed. Or when it grabs new urls and 50 of them are dupes it will output; "Loaded 50/100 URLs".
I think this is how it works though, not sure. Would be nice if someone could correct/verify this?
cander
Remove duplicate URL don't stop to freeze and block GSA SER v.6.31 I've tried 10 times and still freezing
I've then tried Remove duplicate URL only for 2 sitelist_Web 2.0-cineblog.br and still freezing what's the solution ?
hans51
From manually looking at 10'000+ article sites in my early beginning of article submission late 2010, I noticed that there are a number of domains that have NO link to any article sites existing on same domain
but their entire article directory is "hidden" in a subfolder or sub/sub folder hence by removing dups to the domain level
you may remove those DEEP links leading to any page of the article directory
a similar situation (less verified - but repeatedly experienced on .gov and .edu sites exists with wiki and blogs NOT linked from domain level index page.
one particular domain may have a deep link to a blog and another deep link to a wiki or article site
by de-dup to domain you may lose one or all of a.m.
ron SERLists.com
I think an official answer should be added to the unofficial FAQ.
I just looked, and I don't see it in there.
cander
Some footprint were in the files sitelist_Web 2.0-cineblog.fr.
So I've delete all the URLs include in the files sitelist_Web 2.0-cineblog.fr and now remove duplicate URL works
Comments
I only every use remove duplicate urls. And do a couple of hundred thousand to a million every couple of days when I run it
Duplicate domains, I do not touch
But thats just my own preference and how I build my own links
@Ozz, sorry, I should know at this point to look at that thread
P.s @LeeG, that's the way that I like to do things too.
Lets say I run a new project and have use sitelist turned on. It will grab 100 urls from the sitelist, but if 50 of these are from the same domain it will say 49 times: "already parsed" right? Because it tried to post to the first url and after that it will identify: hey I have already tried to post on this domain so I will output: already parsed. Or when it grabs new urls and 50 of them are dupes it will output; "Loaded 50/100 URLs".
I think this is how it works though, not sure. Would be nice if someone could correct/verify this?
I've tried 10 times and still freezing
I've then tried Remove duplicate URL only for 2 sitelist_Web 2.0-cineblog.br and still freezing
what's the solution ?
I noticed that there are a number of domains that have NO link to any article sites existing on same domain
but their entire article directory is "hidden" in a subfolder or sub/sub folder
hence by removing dups to the domain level
you may remove those DEEP links leading to any page of the article directory
a similar situation (less verified - but repeatedly experienced on .gov and .edu sites exists with wiki and blogs NOT linked from domain level index page.
one particular domain may have a deep link to a blog
and another deep link to a wiki or article site
by de-dup to domain you may lose one or all of a.m.
I think an official answer should be added to the unofficial FAQ.
I just looked, and I don't see it in there.