GSA SER Says “No targets left” Even Though I Imported Millions of Identified URLs — What’s Going On?

Hey guys,
I really need help figuring this out because something is not adding up at all.
I imported a little over 6 million identified URLs into one project.
I ticked all platforms, disabled search engines, and set the project to use my global site list → Identified folder.
After less than 2 days, I get this message:
“No targets to post to (no search engines chosen, no url extraction chosen, no scheduled posting)”
There is no way SER processed 6 million URLs in under 48 hours with LPM 20–30 and 100 threads. Not even close.
So I tried again…
This time I created separate projects per platform (Articles, Blog Comments, Guestbooks, etc.).
Instead of letting SER pull from the global site list automatically, I imported platform-specific URLs into each project manually.
Same result — after a short period:
“No targets left to post”
How can this be possible when I have almost 3 million Article URLs alone, and tons more across other platforms?
Did anyone run into this before?
Is SER skipping URLs?
Is there some filtering, footprint detection, or caching behavior deleting targets I’m not aware of?
Any insight would help because this makes absolutely no sense right now.


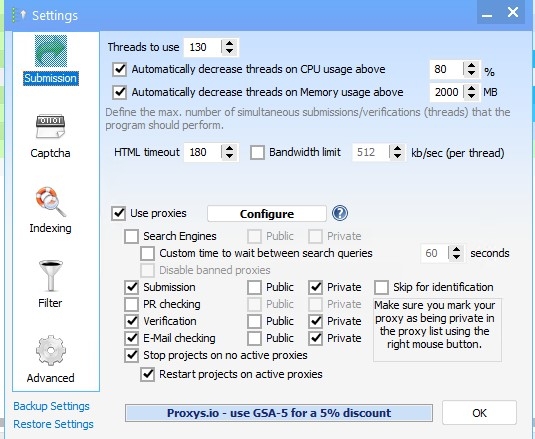

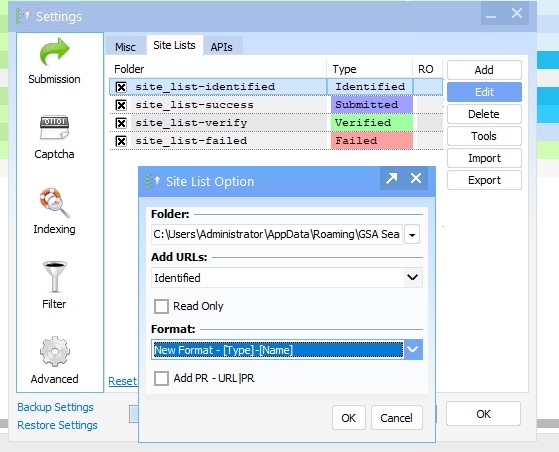











And last picture options are like above only difference all platforms are ticked and it's fetching from global site list "Identified" instead of importing in project list directly.
Comments
I understand that just because a URL is in the Identified list it doesn’t mean SER will be able to post to it — that part is clear.
But that’s not the issue I’m talking about.
My point is:
SER could not have processed all those URLs in under 2 days, regardless of whether they are postable or not.
Processing = loading the URL, checking the engine footprint, parsing it, and determining whether it’s usable. Even if 90% are trash or unpostable, SER still needs to touch them.
With 6+ million URLs, LPM 20–30, and 100 threads, there is simply no way SER went through the entire list that fast. That is why the “No targets left” message makes no sense.
For example:
Even at an unrealistic rate of 100 LPM, it would still take almost 42 hours just to look at 250k URLs — not millions. And I’m nowhere near 100 LPM.
So the question is:
Why is SER stopping early as if it already processed everything?
– Is it skipping URLs?
– Is it ignoring whole chunks of the list?
– Is it hitting a cache limit or memory limit?
– Is there deduping going on across projects?
– Is global site list conflicting with project-imported lists?
– Is SER filtering by engine footprint incorrectly?
That’s what I’m trying to figure out.
I know the list isn’t fully postable — but SER should still go through all 6 million URLs, and it clearly isn’t. That’s the actual problem.
If anyone has experienced SER stopping early like this or skipping large portions of site lists, I’d appreciate some insight.
Hi @cherub ,
They are identified URLs and domains, but duplicates are already cleared.
I’m using the auto dedupe option in SER — so only unique URLs are kept for Blog Comments, Guest Posts, Image Comments, and Trackbacks, and unique domains are kept for all other engines.
My understanding is that SER automatically knows which engines require URL-level deduping and which require domain-level, so when I select the auto option, it deletes:
duplicate URLs for engines like blog comments, guestbooks, image comments, trackbacks
duplicate domains for engines that only allow one submission per domain (articles, wikis, social networks, etc.)
Is that correct?
Because if so, then the list I’m feeding SER is already reduced to unique targets per engine. Which means SER should still have far more targets available than what it reports when it stops and says “No targets left.”
Just want to confirm that I’m understanding the deduping logic correctly.
Hey @googlealchemist
I added it in first post, for Article platform it's mostly 90 % Wordpress engine sites and they suck badly, most of them are not postable and has registration disabled or no form to submit and even when you submit they rarely get verified, that engine sucks it's highly moderated so no use submitting to it no matter what kind of content you do they will get deleted eventually.
i thought maybe it was maybe from you haveing the 'dont submit the same article more than 2 times per domain' enabled with only one article in there...but that would only be relevant if u had 'post to the same domain' enabled which u dont...and more relevant for testing many inner pages of the same domain for comments vs the main article sites which i see is the only engine u have enabled.