Maximizing GSA Proxy Scraper
After a few days playing with GSA Proxy Scraper, I successfully found quality proxies for different purposes, which is including web scraping, captcha solving, etc.
Following is an example of using the public proxies with Xevil for ReCaptcha solving:

GSA Proxy Scraper is a powerful tool, and you can do mostly everything proxy-related with it if you understand what you're doing. So how can you get this result?
1. TAGs and Proxy Tests:
First, you will need to understand that you won't be able to get the proxies that you want if you're not using Tags and Proxy Tests correctly. With Tags, you can tell which websites that you can use the proxy for; and testing is how you can get the tags automatically.
From a quick researching, I found out that Financial Institutions/Streaming Services/Government websites are the hardest ones to bypass using proxies, which mean using them as the tests would return quality proxies.
-----------------------------------
Quick explanation about the bug:
For example {user}\AppData\Roaming\GSA Proxy Scraper\test_data\Google Recaptcha v2.ini
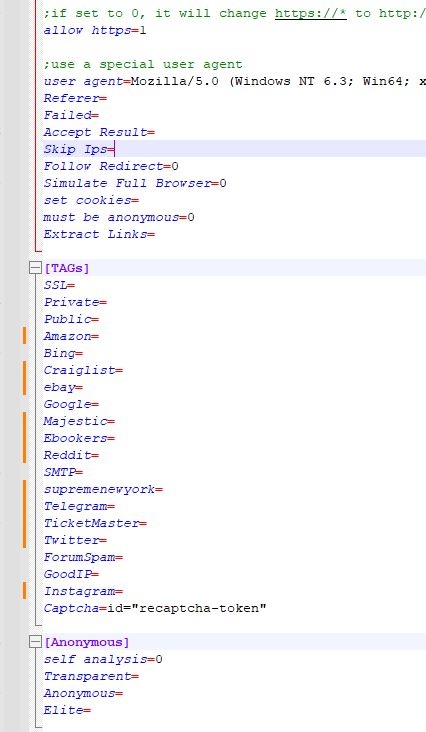
Under TAGs, there are default Tags, even though it's empty after '=' for most of the value, the tool will still try to add back these tags if it's not in the current tags. Adding ';' or removing the line completely will fix it, making sure the unused tags won't be added.
-----------------------------------
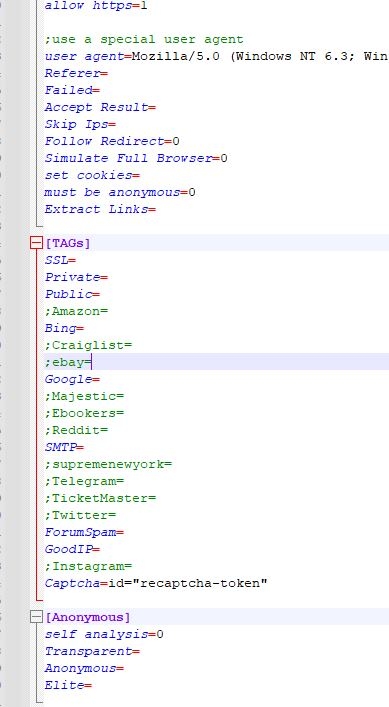
To avoid the conflict, I edit ini files manually without running the tool.
Tags setting: {user}\AppData\Roaming\GSA Proxy Scraper\config.ini
This is where define which Tags you're using. There will be 16 tags total for editing (14 without Private/Public)

For example, I'm editing #3-6, which are Financial/Streaming/Captcha/Gov with color code.
Idea: I'm going to add 3-5 test for each Financial/Streaming/Gov, so if we're passing any in 3-5, we're getting that Tag (passing 1 in 5 'Financial' tests for 'Financial' tag, getting all Financial/Streaming/Gov tag for high quality proxy) and Captcha is for ReCaptcha, where i'm using the proxy with.
Tests: {user}\AppData\Roaming\GSA Proxy Scraper\test_data\{test}.ini
Keeping all of the Anonymity tests the same (the following photo is from the tool), we're removing all of the unused TAGs that mentioned in Quick explanation about the bug and matching the 16 TAGs that we're keeping in config.ini)

If you're used to editing ini files, you can easily create copy of 'Amazon.ini' test (for example) and then rename + edit to the needed test. Following, I will show how to create the test using the tool for better visual:

You will get a box like following:

This is my 'Bank of America' Test for Financial (you will need to go the website, turn on developer console or F12, look for something like title or logo, make sure that it won't be changed in the future soon; and use it as string).

From this example, i'm using '<title>Bank of America' as string for success and Financial/SSL tag.
So from this test, if the proxy can go to bankofamerica.com, find '<title>Bank of America' string (loading successfully), that proxy will get 'Financial' and 'SSL' tag.
Keep repeating this step until you get 5 Financial, 5 Streaming, 5 Gov websites so we only need to pass 1 of 5 to get the Tag for that category, avoiding being too hard on the tests.
For the 'Captcha' tag, I'm updating the existing 'Google Recaptcha v2' test, making sure we know the proxy passed 'Google Recaptcha v2' so we can use later.
After finishing, make sure to 'Test' all of the tests, making sure it's working correctly with our real IP (shouldn't be blacklisted/banned)
----------------------------------------------------------------------
2.Sources and auto searching:
First, please read this thread carefully since I don't want to repeat existing info:
https://www.gsa-online.de/gsa-forum/#/discussion/30439/finding-reliable-fast-stable-proxies
In this thread, I'm going to introduce a powerful tool that can help you find millions of proxy and how to add quality sources for further auto-searching!!!!!
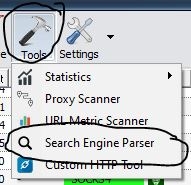
From Tools, we're picking 'Search Engine Parser', this tool will help you find URLs from search engines with input keywords. We will use this list of URLs for finding proxies later.

In keywords, we're putting as many keywords that we can think of when searching for proxy list as possible (you can use chatgpt to generate a list). To be more advanced, you can do a quick SEO research on keywords (the less volume and the harder the keyword to rank the better since less people know with more high quality sites). PLEASE NOTE THAT IT WILL TAKE HOURS/DAYS UNTIL GETTING THE PROXIES IF THE LIST IS TOO LONG.
In Search Engines, we're picking all of the engines, since I'm not really sure which one is good.
In Options, we're keeping 'All' for proxies tag (unless you have a good amount of Tagged proxies). For the number of thread, the more the faster, but make sure you PC can handle it and you have enough proxies avoiding spamming (we can't keep searching with the same IP), and I leave 'Use the same proxy for same search engine/keyword' unchecked
Now we can press 'Start' on the right side. It will take a few hours if you got a good amount of keywords, it will take a few hours to find URLs from search engines!!!
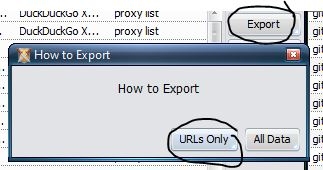
After finishing, we're exporting the URLs to a txt file

-----------------------------------
Now we got the list of URLs, our next step is to extract proxies from these URLs then test them
Here is how you can input the txt file that we saved:
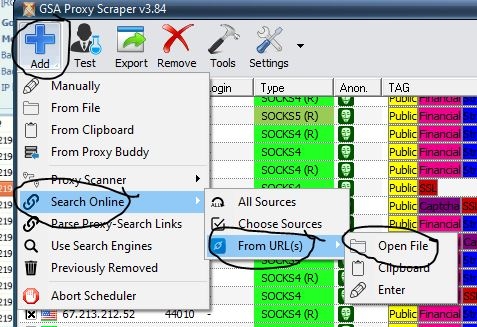
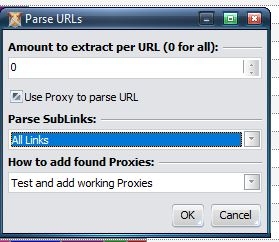
AND IGNORE PROXY SCRAPER FOR A FEW HOURS SINCE IT WILL BE CRAZY LONG!!!!

Remember that this is only extracting proxies, there will be filtering and then testing the proxies after!!! SO PLEASE BE PATIENT!!!

There will be a report table after the testing is finished, this is where you can get the quality proxy sources here for auto-searching!!!
From the table, we're sorting by the proxies working. 'Copy selected' for all of the sources that got 1 or more working proxies

Note: this above table is just a quick search for photo capturing, that's why I only got 1 working proxy here
Now we can add these sources to provider, where the tool will automatically look for new working proxies later!!!

I will update the thread later about exporting automatically picking proxies with Captcha + Financial + Streaming + Gov tags for using.
Following is an example of using the public proxies with Xevil for ReCaptcha solving:
GSA Proxy Scraper is a powerful tool, and you can do mostly everything proxy-related with it if you understand what you're doing. So how can you get this result?
1. TAGs and Proxy Tests:
First, you will need to understand that you won't be able to get the proxies that you want if you're not using Tags and Proxy Tests correctly. With Tags, you can tell which websites that you can use the proxy for; and testing is how you can get the tags automatically.
From a quick researching, I found out that Financial Institutions/Streaming Services/Government websites are the hardest ones to bypass using proxies, which mean using them as the tests would return quality proxies.
-----------------------------------
Quick explanation about the bug:
For example {user}\AppData\Roaming\GSA Proxy Scraper\test_data\Google Recaptcha v2.ini
Under TAGs, there are default Tags, even though it's empty after '=' for most of the value, the tool will still try to add back these tags if it's not in the current tags. Adding ';' or removing the line completely will fix it, making sure the unused tags won't be added.
-----------------------------------
To avoid the conflict, I edit ini files manually without running the tool.
Tags setting: {user}\AppData\Roaming\GSA Proxy Scraper\config.ini
This is where define which Tags you're using. There will be 16 tags total for editing (14 without Private/Public)
For example, I'm editing #3-6, which are Financial/Streaming/Captcha/Gov with color code.
Idea: I'm going to add 3-5 test for each Financial/Streaming/Gov, so if we're passing any in 3-5, we're getting that Tag (passing 1 in 5 'Financial' tests for 'Financial' tag, getting all Financial/Streaming/Gov tag for high quality proxy) and Captcha is for ReCaptcha, where i'm using the proxy with.
Tests: {user}\AppData\Roaming\GSA Proxy Scraper\test_data\{test}.ini
Keeping all of the Anonymity tests the same (the following photo is from the tool), we're removing all of the unused TAGs that mentioned in Quick explanation about the bug and matching the 16 TAGs that we're keeping in config.ini)
If you're used to editing ini files, you can easily create copy of 'Amazon.ini' test (for example) and then rename + edit to the needed test. Following, I will show how to create the test using the tool for better visual:
You will get a box like following:
This is my 'Bank of America' Test for Financial (you will need to go the website, turn on developer console or F12, look for something like title or logo, make sure that it won't be changed in the future soon; and use it as string).
From this example, i'm using '<title>Bank of America' as string for success and Financial/SSL tag.
So from this test, if the proxy can go to bankofamerica.com, find '<title>Bank of America' string (loading successfully), that proxy will get 'Financial' and 'SSL' tag.
Keep repeating this step until you get 5 Financial, 5 Streaming, 5 Gov websites so we only need to pass 1 of 5 to get the Tag for that category, avoiding being too hard on the tests.
For the 'Captcha' tag, I'm updating the existing 'Google Recaptcha v2' test, making sure we know the proxy passed 'Google Recaptcha v2' so we can use later.
After finishing, make sure to 'Test' all of the tests, making sure it's working correctly with our real IP (shouldn't be blacklisted/banned)
----------------------------------------------------------------------
2.Sources and auto searching:
First, please read this thread carefully since I don't want to repeat existing info:
https://www.gsa-online.de/gsa-forum/#/discussion/30439/finding-reliable-fast-stable-proxies
In this thread, I'm going to introduce a powerful tool that can help you find millions of proxy and how to add quality sources for further auto-searching!!!!!
From Tools, we're picking 'Search Engine Parser', this tool will help you find URLs from search engines with input keywords. We will use this list of URLs for finding proxies later.
In keywords, we're putting as many keywords that we can think of when searching for proxy list as possible (you can use chatgpt to generate a list). To be more advanced, you can do a quick SEO research on keywords (the less volume and the harder the keyword to rank the better since less people know with more high quality sites). PLEASE NOTE THAT IT WILL TAKE HOURS/DAYS UNTIL GETTING THE PROXIES IF THE LIST IS TOO LONG.
In Search Engines, we're picking all of the engines, since I'm not really sure which one is good.
In Options, we're keeping 'All' for proxies tag (unless you have a good amount of Tagged proxies). For the number of thread, the more the faster, but make sure you PC can handle it and you have enough proxies avoiding spamming (we can't keep searching with the same IP), and I leave 'Use the same proxy for same search engine/keyword' unchecked
Now we can press 'Start' on the right side. It will take a few hours if you got a good amount of keywords, it will take a few hours to find URLs from search engines!!!
After finishing, we're exporting the URLs to a txt file
-----------------------------------
Now we got the list of URLs, our next step is to extract proxies from these URLs then test them
Here is how you can input the txt file that we saved:
AND IGNORE PROXY SCRAPER FOR A FEW HOURS SINCE IT WILL BE CRAZY LONG!!!!
Remember that this is only extracting proxies, there will be filtering and then testing the proxies after!!! SO PLEASE BE PATIENT!!!
There will be a report table after the testing is finished, this is where you can get the quality proxy sources here for auto-searching!!!
From the table, we're sorting by the proxies working. 'Copy selected' for all of the sources that got 1 or more working proxies
Note: this above table is just a quick search for photo capturing, that's why I only got 1 working proxy here
Now we can add these sources to provider, where the tool will automatically look for new working proxies later!!!
I will update the thread later about exporting automatically picking proxies with Captcha + Financial + Streaming + Gov tags for using.
Thanked by 3Sven Ritchievalens highsave
Comments
Thanks