already parsed - and other things
 the_other_dude
USA
the_other_dude
USA
Hi,
Currently I am scraping URLs with scrapebox and custom tools. I have GSA PI monitoring those folders where my raw scrape lists are stored. The URLs are filtered by GSA PI and stored in the default SER identified list.
Issue 1: my verified link list creation project is set to automatically get links from the identified link list in the default identified folder, but SER does not automatically get fresh links from the identified site list. Instead I have to manually import target urls from the identified site list for SER to start doing anything after it runs out of links in the target link list.
Issue 2: SER does not remove the URLs from the identified link list once it has parsed them the first time. Is SER supposed to move URLs to submitted, verified or failed link lists if building them is enabled once it has parsed the links and submitted, verified, or failed?
Every time I import the URLs from the identified site list, SER spends most of its time parsing already parsed urls, since they are not being moved to different folders. is this normal? Do I need to change my settings?
Thank you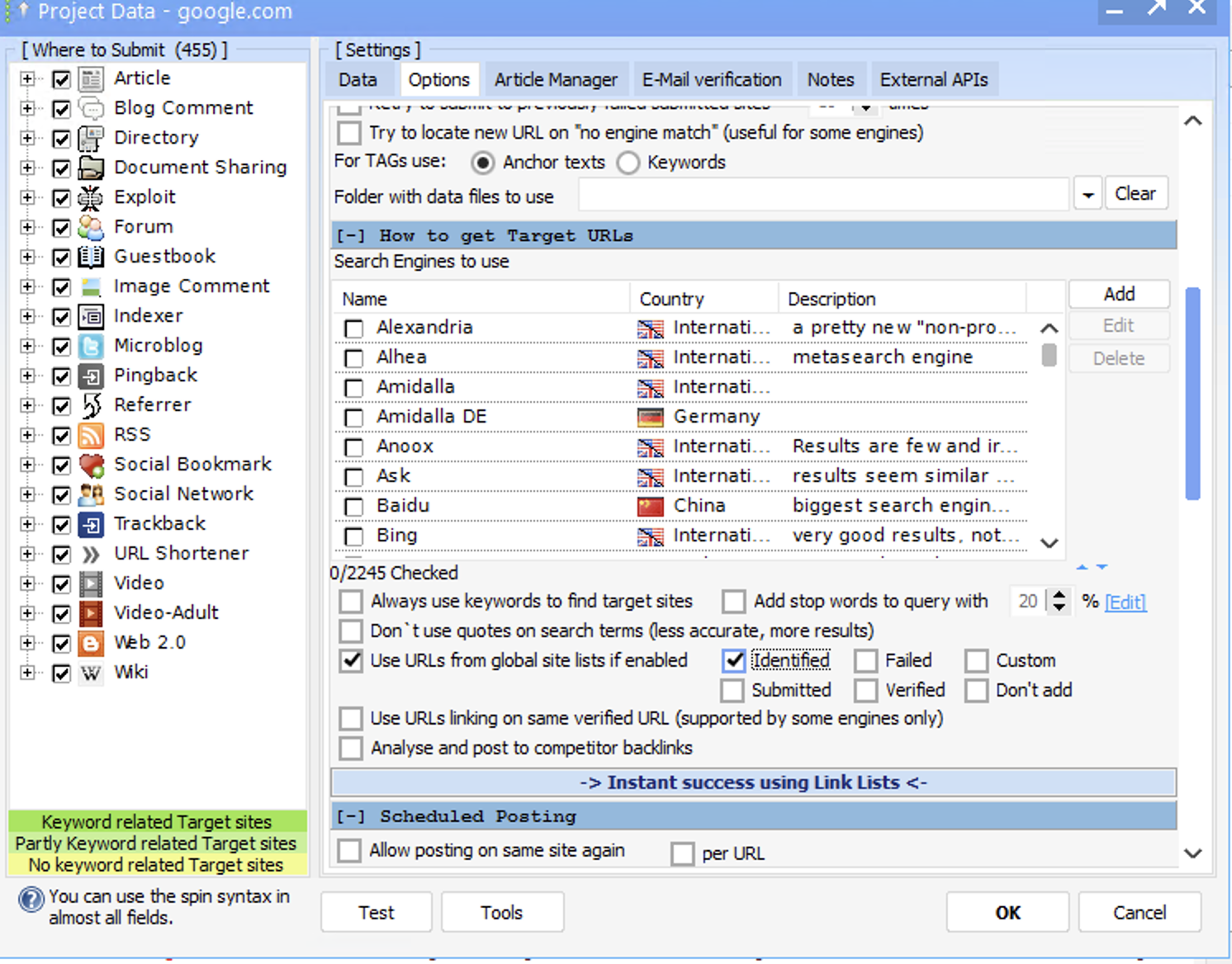

Currently I am scraping URLs with scrapebox and custom tools. I have GSA PI monitoring those folders where my raw scrape lists are stored. The URLs are filtered by GSA PI and stored in the default SER identified list.
Issue 1: my verified link list creation project is set to automatically get links from the identified link list in the default identified folder, but SER does not automatically get fresh links from the identified site list. Instead I have to manually import target urls from the identified site list for SER to start doing anything after it runs out of links in the target link list.
Issue 2: SER does not remove the URLs from the identified link list once it has parsed them the first time. Is SER supposed to move URLs to submitted, verified or failed link lists if building them is enabled once it has parsed the links and submitted, verified, or failed?
Every time I import the URLs from the identified site list, SER spends most of its time parsing already parsed urls, since they are not being moved to different folders. is this normal? Do I need to change my settings?
Thank you
Comments