Bug report
Hello Sven,
Before starting, a
big THANK YOU for this powerful tool that is GSA CG, I only recently
acquired it but I am already very enthusiastic about the uses I will
be able to make of it!
And above all, CONGRATULATION for the
exemplary follow-up that the tool has been undergoing since its
launch, as I understand that updates are regularly made to push the
tool even further (+ the fact that you are particularly attentive to users' requests).
As I got to grips with GSA CG and the tests
I was able to perform to better understand the software, I
encountered several problems, and was unable to produce truly optimal
results. I have several ideas to propose but first of all, here are
some bugs (or misuses ?) I encountered during my sessions :
1)
Foreign language content in the text : I generate texts in French,
but my test theme being "marketing" many technical words
are in English. So, I guess the tool has scraped foreign language
contents. Unfortunately these elements were not filtered in the final
rendering, and I end up with paragraphs entirely in English.
Is it
possible to filter these unwanted contents ? Or, at least, offer the
possibility to automatically filter these content once the generation
is complete, even if it means losing a bit of time in the process
?
Here is a resource that might be useful, after some research on
the subject (even if I don't know in which language you coded the
software...): https://github.com/landrok/language-detector
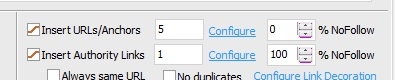
2)
When I ask the tool to generate exactly 5 anchors in my texts, I end
up with less than 5 anchors in the content (between 1 and 5 anchors to be
more precise), even though I didn't write "1-5" in the concerned field.
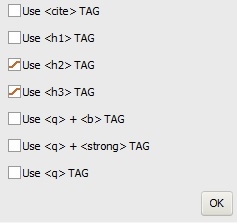
3) While I specify that I
don't want H1 in my texts (see screenshot), I often end up with H1 at
the beginning of my articles.
Moreover, these H1s are followed by H3
(which is not logical from a structural point of view).
4) I
don't know if it's a bug or if it's something intentional, but empty paragraphs
appear in my generation.

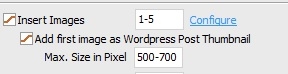
5) Although "Add
first image as Wordpress Post Thumbnail" is checked, "wp-post-image" is not
attributed to the first image in the article, but to a random one.
6) The alt tags of the images are almost all
the same, instead of digging into the keywords and making the alt
tags as different as possible from each other.
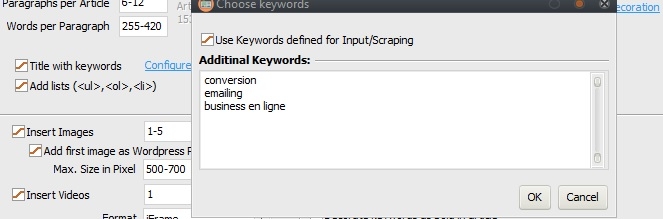
7) I probably
misunderstood the function of the "Title with keywords"
option, but when I enter additional keywords in the appropriate
field, these keywords never appear in my titles.
Thank you very much for the time you spent
reading this report, I wish you good luck for the rest!
On my side
I will try to write down my ideas to flesh out the software ![]()
Take
care !
Comments
I PMed you the backup